
Der KI-Modell-Markt April 2026 ist unübersichtlicher denn je. GPT-5.4 von OpenAI, Claude Sonnet 4.6 von Anthropic, Gemini 3 von Google – alle drei Anbieter versprechen das „beste Modell der Welt". Was stimmt, was ist Marketing? Die aktuellen Benchmark-Daten geben Aufschluss. Und das Ergebnis überrascht: Es gibt keinen klaren Sieger – aber sehr klare Stärken und Schwächen.
Direkte Antwort: Im April 2026 führt Claude Sonnet 4.6 von Anthropic das GDPval-AA-Elo-Ranking mit 1.633 Punkten an. GPT-5.4 von OpenAI dominiert bei Computer-Use-Benchmarks und Coding-Tasks. Gemini 3 punktet bei multimodalen Aufgaben und Google-Dienste-Integration. Welches Modell „besser" ist, hängt vom konkreten Anwendungsfall ab.
Der Überblick: Welche Modelle sind im April 2026 relevant?
Drei große Player dominieren den Frontier-KI-Markt im Frühjahr 2026: OpenAI mit GPT-5.4 (erschienen März 2026), Anthropic mit Claude Sonnet 4.6 und Claude Opus 4.6, sowie Google mit Gemini 3. Hinzu kommen spezialisierte Varianten wie GPT-5.4-Cyber (für Sicherheitsanwendungen) und verschiedene Open-Source-Modelle wie Llama 4. Kurz gesagt: Der KI-Markt 2026 ist kein Duopol mehr – es ist ein Dreikampf mit wachsender Open-Source-Flanke. Was das für normale Nutzer bedeutet: Auswahl, aber auch Verwirrung.
📋 Quick Facts
• Frontier-Modelle: GPT-5.4 (OpenAI), Claude Sonnet/Opus 4.6 (Anthropic), Gemini 3 (Google)
• Claude Sonnet 4.6 führt GDPval-AA-Elo mit 1.633 Punkten – nahezu auf Opus-Niveau zum Sonnet-Preis
• GPT-5.4 erzielt Rekordwerte bei Computer-Use (OSWorld, WebArena) und erzielt 83% auf GDPval
• Gemini 3 dominiert multimodale Aufgaben und ist tief in Google Workspace integriert
GPT-5.4: Der Alleskönner mit Computer-Use-Fokus
OpenAIs GPT-5.4 ist das erste Allzweck-Modell mit nativer, wettbewerbsfähiger Computer-Use-Kapabilität – es kann also eigenständig Software bedienen, Formulare ausfüllen und Aktionen im Browser ausführen. Mit 83% auf dem GDPval-Test und Rekordwerten auf OSWorld-Verified und WebArena positioniert sich GPT-5.4 klar als das leistungsstärkste Modell für agentenbasierte Aufgaben. Das heißt: Wer KI nicht nur zum Fragen beantworten, sondern zum eigenständigen Handeln einsetzen will, ist mit GPT-5.4 heute am besten bedient. Die Frage ist, wie lang dieser Vorsprung hält – Anthropic hat bereits einen internen Nachfolger in Entwicklung. Ein Blick auf die ChatGPT-Ausfälle 2026 zeigt aber auch die Kehrseite der intensiven Nutzung: ChatGPT-Ausfall 2026 – was dahintersteckt.
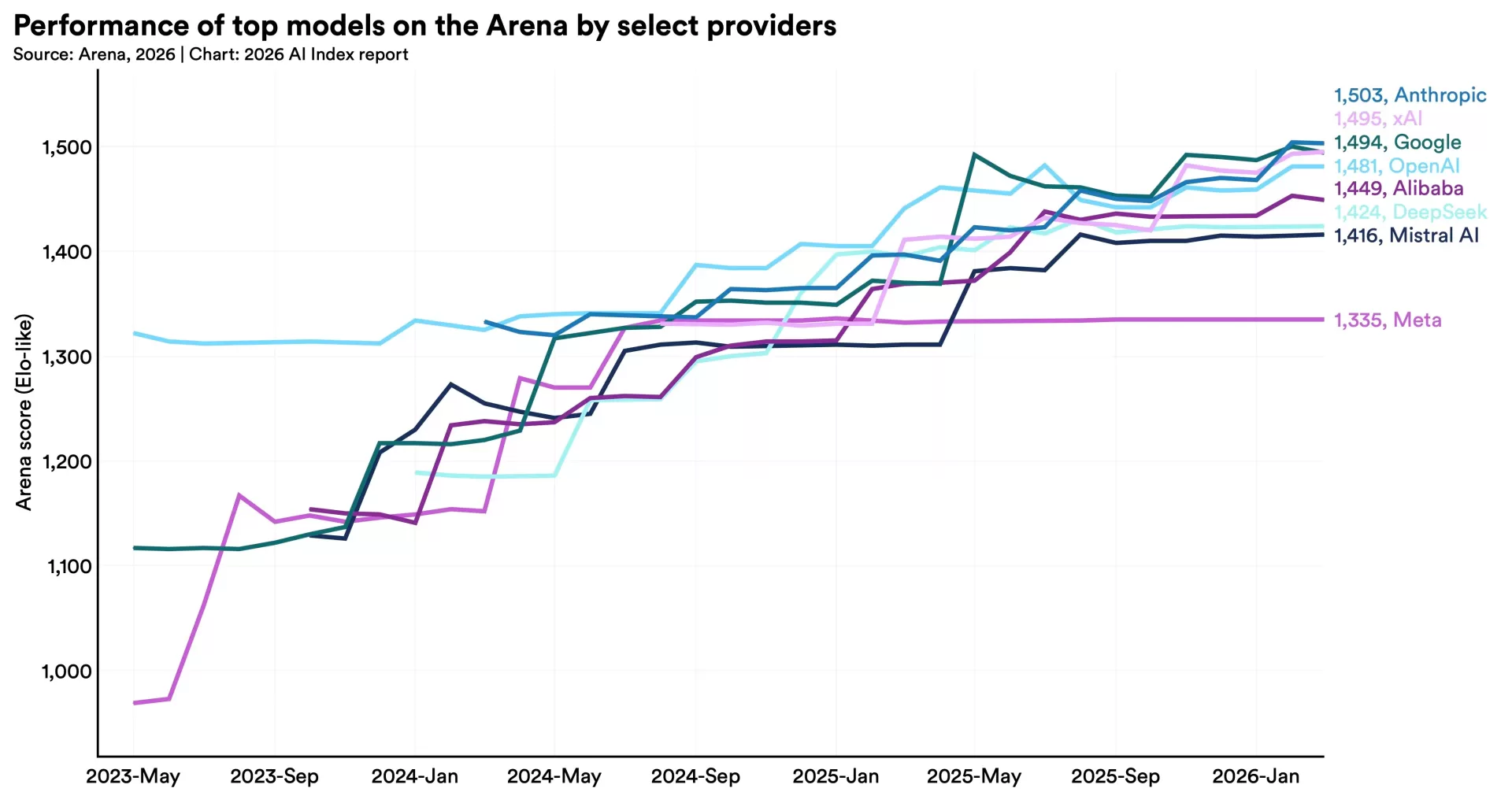 Claude Sonnet 4.6: Effizienz trifft Spitzenleistung
Claude Sonnet 4.6: Effizienz trifft Spitzenleistung
Anthropics Claude Sonnet 4.6 ist das überraschendste Modell des Quartals: Es liefert Leistung nahe am teureren Opus-Niveau, aber zum günstigeren Sonnet-Preis. Das GDPval-AA-Elo von 1.633 Punkten ist das höchste im Ranking – und das bedeutet, dass Claude Sonnet 4.6 bei allgemeinen Aufgaben, Reasoning und Texterstellung heute das stärkste Modell ist. Wer KI regelmäßig für komplexe Analyse- oder Schreibaufgaben nutzt, bekommt mit Claude Sonnet 4.6 das aktuell beste Preis-Leistungs-Verhältnis im Frontier-Segment. Was Anthropic als nächstes plant, deutet das interne "Claude Mythos"-Projekt an – ein mögliches 10-Billion-Parameter-Modell. Mehr dazu im Artikel zu Anthropic Claude Opus 4.7.
🔍 KI-Modelle April 2026 auf einen Blick
GPT-5.4: bestes Computer-Use-Modell, 83% GDPval · Claude Sonnet 4.6: höchster GDPval-AA-Elo (1.633), bestes Preis-Leistungs-Verhältnis · Gemini 3: führend bei Multimodal und Google-Integration · Open-Source: Llama 4 als starke Alternative im Enterprise-Segment
Gemini 3 und die Multimodal-Frage
Googles Gemini 3 setzt andere Prioritäten. Bei Text-only-Benchmarks liegt es hinter GPT-5.4 und Claude Sonnet 4.6 – aber bei multimodalen Aufgaben (Bild, Audio, Video kombiniert) ist Gemini 3 das stärkste Modell. Praktisch bedeutet das: Für Aufgaben, die Bild-Analyse, Dokumentenverarbeitung oder Video-Verständnis kombinieren, ist Gemini 3 die erste Wahl. Hinzu kommt die tiefe Integration in Google Workspace – wer Gmail, Docs und Drive täglich nutzt, profitiert von Gemini 3 mehr als von GPT-5.4 oder Claude. Der Einsatz in OpenAIs eigenen Biologie-Projekten zeigt unterdessen, wohin die KI-Forschung insgesamt steuert: GPT Rosalind: OpenAIs KI für Biologie-Forschung.
Häufige Fragen (FAQ)
Welches KI-Modell ist im April 2026 das beste?
Es gibt keinen universellen Sieger. Claude Sonnet 4.6 führt den GDPval-AA-Elo an, GPT-5.4 dominiert bei Computer-Use-Tasks, Gemini 3 bei Multimodal. Die Wahl hängt vom Anwendungsfall ab.
Was ist der Unterschied zwischen GPT-5.4 und GPT-5.4-Cyber?
GPT-5.4-Cyber ist eine spezialisierte Variante für Cybersecurity-Anwendungen mit erweiterten Berechtigungen für Penetrationstests und Sicherheitsanalysen – sie ist nicht für den allgemeinen Verbrauchermarkt gedacht.
Wann kommt Claude Opus 4.7 oder ein neues Topmodell von Anthropic?
Intern soll Anthropic an einem Modell namens "Claude Mythos" arbeiten, das mit bis zu 10 Billionen Parametern eine neue Leistungsklasse definieren soll. Ein Releasedatum ist nicht bestätigt.
Lohnt sich der Wechsel von GPT-4 auf ein 2026er Modell?
Absolut. Die Leistungssprünge zwischen GPT-4 (2023) und den aktuellen Frontier-Modellen 2026 sind enorm – insbesondere bei Reasoning, Coding und agentenbasiertem Handeln. Ein Upgrade ist für intensive Nutzer klar empfehlenswert.
Key Takeaways
- Claude Sonnet 4.6 führt den GDPval-AA-Elo mit 1.633 Punkten – bestes Preis-Leistungs-Verhältnis 2026
- GPT-5.4 ist das stärkste Modell für Computer-Use und agentenbasierte Aufgaben
- Gemini 3 dominiert Multimodal-Benchmarks und Google-Workspace-Integration
- Der KI-Markt ist 2026 ein echter Dreikampf – kein Modell gewinnt auf allen Feldern
- Open-Source-Modelle wie Llama 4 werden im Enterprise-Segment immer wettbewerbsfähiger
Editor Kommentar: Was mich an diesen Benchmarks am meisten beeindruckt: Claude Sonnet 4.6 hat Opus-nahe Leistung zum Sonnet-Preis. Das ist kein kleiner Schritt – das verschiebt das gesamte Preisgefüge im KI-Markt. OpenAI muss reagieren. Was ich vermisse: transparentere Benchmarks. GDPval und Arena-Scores sind nützlich, aber sie messen nicht, was viele Nutzer wirklich brauchen – zuverlässiges, fehlerarmes Arbeiten über lange Kontextfenster. Der nächste große Sprung wird nicht in Benchmark-Punkten messbar sein, sondern in der Frage: Wie oft macht das Modell noch Fehler?
Quelle: MIT Technology Review













